
The queue is the ideal way how to distribute the load to more nodes. This is simple producer vs consumer scenario. The producer generates the work and puts it in the queue. Consumer pulls the work from the queue and processing it. The advantage is that there is no direct link between the producer and the consumer. Connecting a new compute node means just configure a connection to the queue. Which is simple to setup and manage.
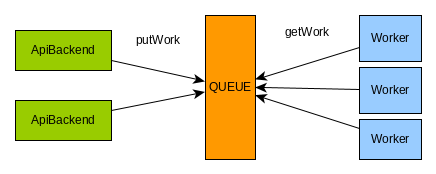
How to implement the queue
The persistent queue should be a central element outside the backend. There are more ways how to implement the queue. One suitable way is to implement the queue in the database.
Database queue
Database queue has several advantages:
- Consistency – We can put data in a queue in the same database transaction. There is no need to worry that the message will be lost or duplicated. This can happen with other solutions, such as RabbitMQ.
- Simple implementation – It is just a couple of SQLs. However you need to be careful about database locking.
- No additional dependency – You do not need additional technology installed in your infrastructure. No additional HA configurations. No additional backups. And less things can go wrong.
There are also disadvantages:
- Database queue is not suitable for high load.
- It is another load on the database. We should be nice on the database because the database is scaling badly.
The database queue is also suitable for email sending. Why? Imagine that we want to send an email in the middle of a database transaction. If an error occurs, the database will rollback and we will return to the previous state. However, the phantom email may have been already sent.
Therefore, it is better to push the email request to the database queue instead. After successful commit to the database, the request is processed by another thread (consumer).
Conclusion
If you want a consistent and simple solution, choose the database. If you can handle some inconsistency and need to process a high amount of messages, choose RabbitMQ or similar solutions.
One thought on “How to scale with the queue”