
How to write a monolithic application? Using monolithic architecture has many advantages over microservice architecture. The code is much simpler, the data is consistent, and the application can be tested well. However, when writing a monolithic application, it is necessary to follow some principles. Otherwise, we run the risk of creating a spaghetti code that does not scale well. So what to watch out for?
Level design
The application needs to be divided into several levels. I use API level, Service level, Repository level and Connector level.
- Repository level – It is only used to access the database. It does not contain any business logic, except in exceptional cases when it is necessary to put this logic into an SQL query/update. The repository sees no other layers. This layer only takes care of the conversion between SQL and JAVA classes.
- Connector level – Similar to repository level. It is only used to communicate with another system. It should hide third party implementation details and complexity.
- Service level – It is the core of the whole system, it contains business logic. It sees and uses Repository and Connector levels. It is also in charge of database locking and database transactions.
- API level – It makes the application available to the rest of the world. The layer should not contain more complex logic. Calls mostly Service level.
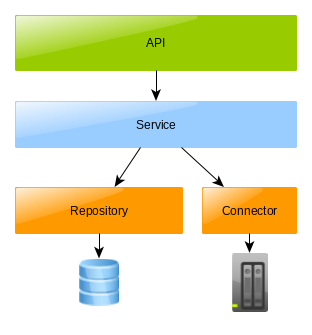
Adhering to this principle is important, otherwise there is a risk of creating spaghetti code.
Multi instances
When writing a backend, one has to think about whether it will run well in multiple instances. This is very important for future scalability.
Having multiple instances is also important in order to deploy new versions of the application seamlessly. When a new version is deployed, the first instance is turned off first, and after the successful deployment, the second instance is turned off. This procedure can be automated, for example, using a script that controls HAProxy.
We can combine scaling with HAProxy and queue. All nodes contain the same backend code. There are two types of nodes:
- API (standard) node – accepts a remote connection and processing easy synchronous tasks.
- Worker node – accepts work from the queue and processing CPU intensive tasks – synchronous or asynchronous (OCR, Excel exports,..)
We can switch from API node to the Worker node by changing configuration settings – typically application.properties file. This simplifies DevOps a lot.
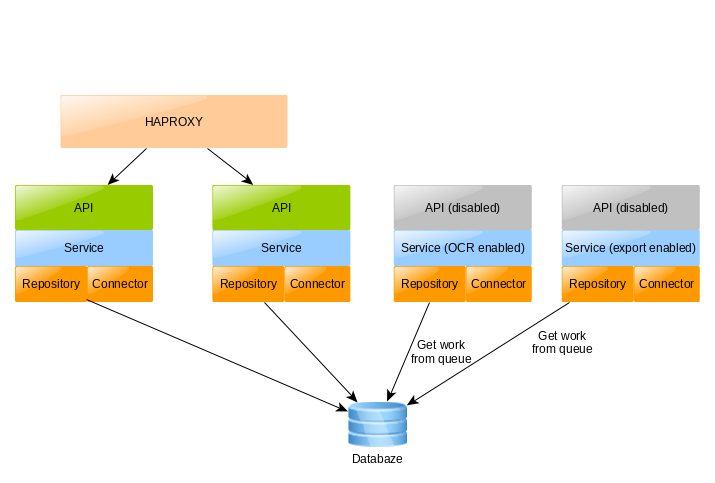
Note that backends do not communicate with each other. This is very convenient and simplifies application development and maintenance.
The disadvantage of this architecture is that there is a central database that scales badly. More information how to scale database.
One thought on “How to write a monolithic application”